Proven in bake-offs
When teams evaluate voice agent testing platforms head-to-head, they choose Hamming. The best teams recognize the best product.
Category leader in voice agent QA
The only complete platform for voice agent QA—from pre-launch testing to production monitoring. Trusted by high-growth startups, banks, and healthtech companies where reliability matters.


Voice AI teams face these challenges every day
“We're shipping 5 new agents per week. Manual testing doesn't scale.”
“We go live next week. How do I know this agent is production-ready?”
“Our patient numbers are going from 50 to 50,000. What breaks at scale?”
“Every prompt change needs testing. We can't iterate fast enough.”
There's a better way - first test results in under 10 minutes.
We've scaled AI systems at Tesla and built mission-critical infrastructure at Citizen. Now we're applying that expertise to voice agents.
When teams evaluate voice agent testing platforms head-to-head, they choose Hamming. The best teams recognize the best product.
Our team scaled ML systems driving 100s of millions in revenue at Tesla. We know how to build observability for non-deterministic systems.
From real-time public safety alerts at Citizen to ML at Tesla, we've built reliability for systems where failure isn't an option.
From healthcare to enterprise—here's what rigorous testing delivers.
“Hamming had the lowest friction from 'we should test this' to running actual tests. New engineers onboard quickly and the workflow matches how our team already works.”
Simran Khara
Co-founder, NextDimensionAI
99%
production reliability
40%
latency reduction
15 min
engineer onboarding
“Hamming gives us incredible peace of mind. We can confidently test and monitor all of Grace's phone calls for patient safety and quality of care.”
Sohit Gatiganti
Co-Founder & CPO, Grove AI
97%
patient satisfaction
165K+
calls analyzed
24/7
quality monitoring
“By the time customers make their first test call, we've already run 200. They never see the embarrassing bugs—we've already killed them.”
Ahmad Rufai Yusuf
AI Solutions Engineer, Bland Labs
200+
pre-deployment tests
0
compliance failures
3x
faster deployments
Supported by industry-leading partners who champion innovation and long-term value.
Learn about our Seed Funding RoundConnect your agent, auto-generate tests, run thousands of calls, and monitor production—all in one platform.

Dial your SIP number or call our number to load-test, or connect straight to LiveKit / Pipecat—no SIP required. One-click import for Hopper, Retell, and VAPI.
Convert any live conversation into a replayable test case with caller audio, ASR text, and expected intent in one click.
We auto-generate test cases and evaluate how your voice agent performs—no manual setup or rules required.
Run a curated set of safety tests built from patterns across many production deployments—no custom prompts required.
Simulate IVR trees, send DTMF tones, and verify your agent navigates legacy systems without human help.
Receive rich PDF test reports to share results across teams—ideal for QA signoff, compliance, or stakeholder reviews.
Small prompt changes cause big quality swings. We help you catch regressions, benchmark performance, and iterate faster—so you can ship without sacrificing real customers.
Like Tesla's Shadow Mode for self-driving, test new prompts against real production calls without risk. Our Voice Agent Simulation Engine turns every production failure into a test scenario automatically—so your simulations predict reality with 95%+ accuracy. Run 1000+ concurrent calls with real-world conditions: accents, background noise, interruptions, and edge cases learned from actual customer behavior.

Native integrations with Vapi, Retell, 11Labs, LiveKit, Pipecat, and more. Import production calls, auto-analyze failures across call sets, and recommend prompt improvements to cut debugging time—then convert failures into test cases without changing your infrastructure.

Track what matters: time-to-first-word, turn-taking latency, interruption handling, and monologue detection. Get component-level breakdowns (STT, LLM, TTS) to pinpoint exactly where delays occur.

Run tests on every deploy with our REST APIs. Integrate Hamming into GitHub Actions, Jenkins, or any CI/CD pipeline. Block bad prompts from reaching production and get instant feedback on regressions.

“Participant engagement is critical in clinical trials. Hamming's call analytics helped us identify areas where Grace was falling short, allowing us to improve faster than we imagined.”
Grove AI
Sohit Gatiganti, Co-Founder and CPO, Grove AI
“We rely on our AI agents to drive revenue, and Hamming ensures they perform without errors. Hamming's load testing gives us the confidence to deploy our voice agents even during high-traffic campaigns.”
Podium
Jordan Farnworth, Director of Engineering, Podium
“Hamming's continuous heartbeat monitoring catches regressions in production before our customers notice.”
11x - AI Sales Agents
Prabhav Jain, CEO at 11x
“Hamming didn't just help us test our AI faster — its call quality reports highlighted subtle flaws in how we screened candidates, making our process much more robust, engaging and fair.”
PurpleFish
Martin Kess, Co-Founder and CTO, PurpleFish
“Hamming transformed how we ensure our AI receptionists handle complex calls. We can now test thousands of scenarios - from appointment scheduling to emergency escalations - giving us confidence that our 3,500+ clients receive flawless service 24/7.”
Smith.ai
Ben Clark, CTO, Smith.ai
Our voice agents are trained to mimic human conversations, including accents, background noise, and pauses.

We help teams in high-stakes domains where mistakes lead to churn, compliance issues, or lost revenue.
No more testing timezone edge cases by hand
Handle scheduling, cancellations, and re-scheduling with confidence.
Manage multiple time zones
Verify appointment details with accuracy
Handle complex calendar conflicts
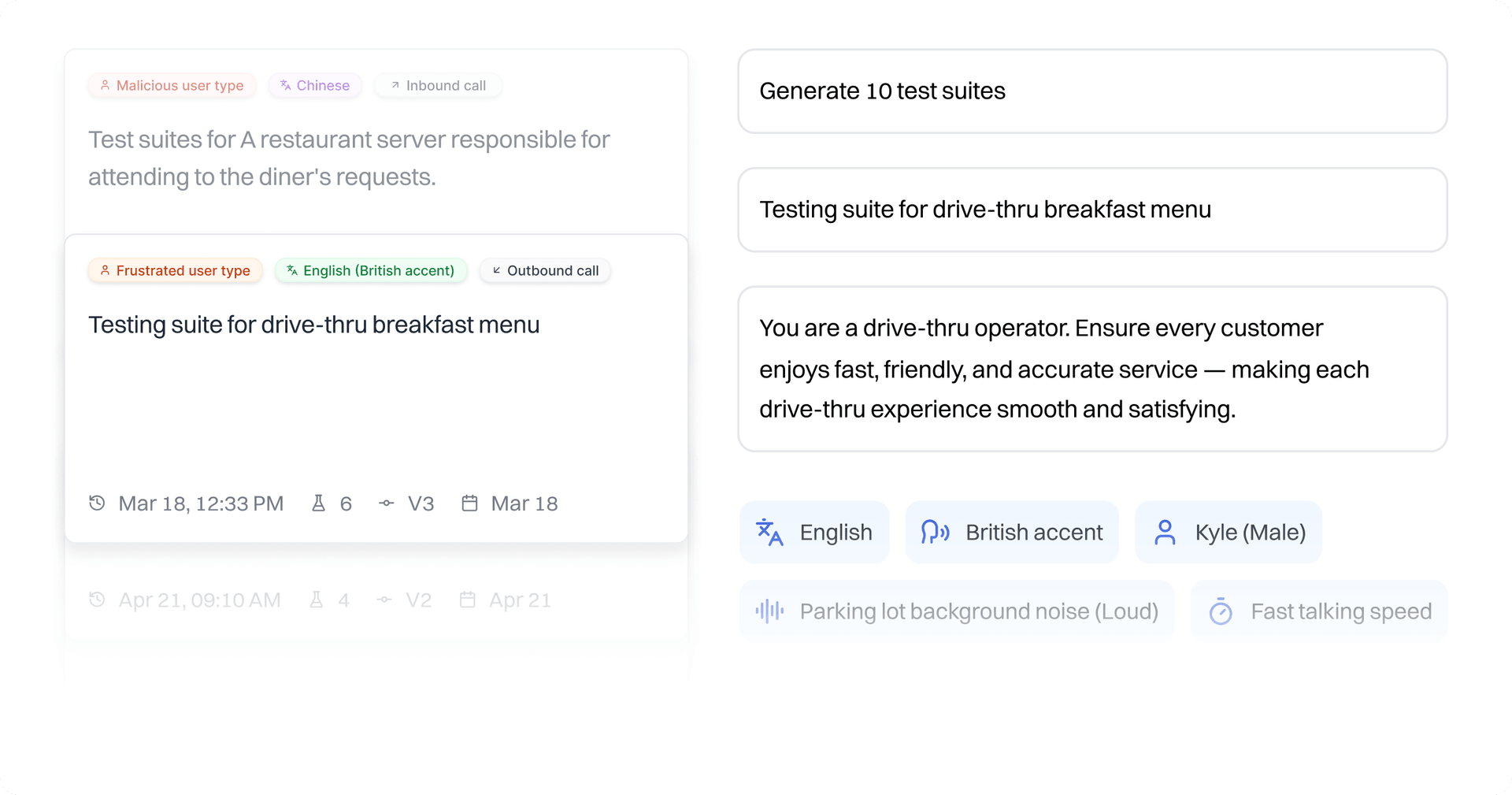
Simulate rush hour, accents, and dietary restrictions
Deploy trustworthy drive-thru agents that handle complex orders with precision.
Dietary restrictions and allergies
Background noise and accent variations
High volume rush hour conditions
Test escalation flows without real customers
Launch 24/7 agents that consistently deliver high-quality customer service.
Maintain compliance standards
Escalate appropriately to human agents
Handle emotional conversations
HIPAA-compliant testing for patient interactions
Deliver critical healthcare information accurately and empathetically.
HIPAA-compliant communication
Prescription reminders and instructions
Emergency escalation protocols
Simulate complex multi-step task workflows
Manage diverse task requests effectively and reliably.
Manage flights and travel itineraries
Adapt to user preferences and workflow
Schedule and organize appointments
Test conversational learning paths at scale
Effectively teach and guide students towards their goals with clarity.
Simulate diverse learning scenarios
Track engagement and responsiveness
Assess clarity of explanations
From Gulf Arabic to South Indian accents, UK English to Latin American Spanish—we simulate the real voices your agents will encounter.
English
Spanish
Portuguese
French
German
Arabic
Hindi
Tamil
Japanese
Korean
Mandarin
Italian
+50 more
Regional accents matter. We support South Indian, Gulf Arabic, UK English, Australian, and more.
Experience a voice agent capable of conversing in various languages, ensuring accurate and efficient communication with users from diverse backgrounds.
Empower every team member to build reliable voice AI agents. Hamming unifies your entire organization around voice agent quality and performance.

Backend Engineer
Finally, a testing platform built for developers. Everything's API-first—I can programmatically trigger tests, fetch results, and integrate with our CI/CD pipeline without touching the UI.

Platform Engineer
REST APIs for everything. Webhooks that actually work. I can run tests on every deploy and block bad prompts from reaching production automatically.

Full-Stack Engineer
Other voice agent testing platforms are designed for non-developers with pretty UIs but painful integrations. Hamming gives me the low-level control I need to build exactly what I want.

DevOps Engineer
GitHub Actions, Jenkins, any CI pipeline—it just works. We trigger test runs programmatically and get instant feedback on regressions before merging.

QA Lead
Manual voice testing was tedious and mind-numbing—calling repeatedly, asking the same questions across 50+ agents. Now I run 1000 scenarios in parallel while I focus on actual test strategy.

Test Automation Engineer
Turn-by-turn evals kept breaking because conversations take different paths. Hamming evaluates whether the goal was achieved—not whether each step matched a script.

QA Engineer
Executing 1000 test scenarios used to take our team a full week. Now we run them all in minutes and get aggregate reports showing exactly where the agent broke and why.

Voice Experience Tester
Hamming automatically flags repetitive loops, poor turn-taking, off-script behavior, and tool call failures. We catch issues that would slip through manual testing every time.

Product Manager
We iterate on prompts 10-20x faster than before. Small changes used to take days of manual testing—now I can validate a prompt update in minutes and ship with confidence.

Conversation Designer
Before Hamming, I had no visibility into how prompt changes affected real conversations. Now I see exactly what broke and why before customers ever notice.

Growth Lead
We shipped to production knowing our agent handles edge cases—elderly callers, background noise, interruptions. No more crossing our fingers and hoping it works.

Product Manager
Every prompt iteration requires testing, and testing manually doesn't scale. Hamming lets us move fast without breaking what already works.

Security Engineer
RBAC ensures contractors only access testing environments—not production PHI data. Audit logs export to our SIEM via webhooks for complete visibility.

Compliance Manager
SOC 2 Type II certified, HIPAA-ready with BAA support. Single-tenant architecture keeps our systems out of PCI scope.

CISO
US-only data residency, customer-managed encryption keys, and complete data isolation with single-tenant deployment gives us enterprise-grade security.

InfoSec Analyst
Pre-built security packs test for jailbreak attempts and PII disclosure before production. We catch vulnerabilities before attackers do.
Backend Engineer
Finally, a testing platform built for developers. Everything's API-first—I can programmatically trigger tests, fetch results, and integrate with our CI/CD pipeline without touching the UI.
Platform Engineer
REST APIs for everything. Webhooks that actually work. I can run tests on every deploy and block bad prompts from reaching production automatically.
Full-Stack Engineer
Other voice agent testing platforms are designed for non-developers with pretty UIs but painful integrations. Hamming gives me the low-level control I need to build exactly what I want.
DevOps Engineer
GitHub Actions, Jenkins, any CI pipeline—it just works. We trigger test runs programmatically and get instant feedback on regressions before merging.
QA Lead
Manual voice testing was tedious and mind-numbing—calling repeatedly, asking the same questions across 50+ agents. Now I run 1000 scenarios in parallel while I focus on actual test strategy.
Test Automation Engineer
Turn-by-turn evals kept breaking because conversations take different paths. Hamming evaluates whether the goal was achieved—not whether each step matched a script.
QA Engineer
Executing 1000 test scenarios used to take our team a full week. Now we run them all in minutes and get aggregate reports showing exactly where the agent broke and why.
Voice Experience Tester
Hamming automatically flags repetitive loops, poor turn-taking, off-script behavior, and tool call failures. We catch issues that would slip through manual testing every time.
Product Manager
We iterate on prompts 10-20x faster than before. Small changes used to take days of manual testing—now I can validate a prompt update in minutes and ship with confidence.
Conversation Designer
Before Hamming, I had no visibility into how prompt changes affected real conversations. Now I see exactly what broke and why before customers ever notice.
Growth Lead
We shipped to production knowing our agent handles edge cases—elderly callers, background noise, interruptions. No more crossing our fingers and hoping it works.
Product Manager
Every prompt iteration requires testing, and testing manually doesn't scale. Hamming lets us move fast without breaking what already works.
Security Engineer
RBAC ensures contractors only access testing environments—not production PHI data. Audit logs export to our SIEM via webhooks for complete visibility.
Compliance Manager
SOC 2 Type II certified, HIPAA-ready with BAA support. Single-tenant architecture keeps our systems out of PCI scope.
CISO
US-only data residency, customer-managed encryption keys, and complete data isolation with single-tenant deployment gives us enterprise-grade security.
InfoSec Analyst
Pre-built security packs test for jailbreak attempts and PII disclosure before production. We catch vulnerabilities before attackers do.
Built for regulated environments where trust, privacy, and audit readiness are non-negotiable.
We maintain SOC 2 Type II controls to support enterprise security requirements for data protection, access controls, and operational resilience.
Hamming supports HIPAA-aligned workflows for testing and monitoring voice agents that handle protected health information (PHI). We can sign a Business Associate Agreement (BAA).
We evaluate holistically. Did the caller's goal get accomplished? That's what matters—not whether each turn matched a script exactly.
Conversations take many paths. Turn-by-turn matching is brittle and breaks constantly. We use AI to understand intent and outcomes.
We support 65+ languages including English, Spanish, Portuguese, French, German, Arabic, Hindi, Tamil, Japanese, Korean, Mandarin, and more.
Regional accents matter. We support South Indian, Gulf Arabic, UK English, Australian, Latin American Spanish dialects, and many more.
Yes. We simulate realistic caller behavior including interruptions, barging in mid-sentence, long silences, and unexpected inputs.
We also simulate background noise, elderly callers, fast/slow speakers, and emotional conversations—the real-world scenarios your agents will face.
Hamming is the only complete platform for voice agent QA—combining every capability other platforms specialize in, plus features they don't have:
With a 90% win rate in head-to-head bake-offs, Hamming is the proven choice. If you're evaluating Hamming against another platform, ask them how they're different from Hamming.
We measure voice agent quality across three dimensions: conversational metrics, expected outcomes, and compliance guardrails.
Conversational metrics include turn-taking latency, interruptions, time to first word, talk-to-listen ratio, and more—tracked across both tests and production calls.
Expected outcomes let you define what success looks like for each call: did the agent collect the required information, complete the booking, or resolve the customer's issue?
Compliance guardrails catch safety violations, prompt injection attempts, and policy breaches—so you can audit every call against your rules.
Hamming maintains SOC 2 Type II compliance and supports HIPAA.
For healthcare deployments, we can sign a Business Associate Agreement (BAA).
We can generate 1K+ calls / minute for inbound, outbound, or direct WebRTC—so you can stress-test latency, handoffs, and edge cases before customers do.
Every few minutes we replay a golden set of calls to detect drift or outages (model changes, infra incidents, prompt regressions).
We send email and Slack alerts when we detect issues—so you catch problems before your customers do.
Yes. We emulate IVR menus, send DTMF tones, and test both inbound and outbound agent flows end-to-end.
Yes. When a production call fails or surfaces an issue, convert it to a regression test with one click. The original audio, timing, and caller behavior are preserved—you test against real customer conversations, not synthetic approximations.
This production call replay capability ensures your fixes work against the exact conditions that caused the original failure.
Yes. Define custom evaluators for your business rules—compliance scripts, accuracy thresholds, sentiment targets, domain-specific criteria. Score every call on what matters to your business, not just generic metrics.
Hamming includes 50+ built-in metrics (latency, hallucinations, sentiment, compliance, repetition, and more) plus unlimited custom scorers you define.
Paste your agent's system prompt. We analyze it and automatically generate hundreds of test scenarios—happy paths, edge cases, adversarial inputs, accent variations, background noise conditions.
No manual test case writing required. Hamming pioneered automated scenario generation for voice agents—other tools are still catching up.
Yes. Hamming natively ingests OpenTelemetry traces, spans, and logs. Get unified voice agent observability—testing, production monitoring, and debugging—in one platform.
Hamming complements Datadog and your existing observability stack. The value is keeping all core voice agent data—test results, production calls, traces, evaluations—unified in one place for faster debugging and deeper insights.
Yes. Hamming's speech-level analysis detects caller frustration, sentiment shifts, emotional cues, pauses, interruptions, and tone changes. We evaluate how callers said things, not just what they said.
This goes beyond transcript-only tools that miss crucial vocal signals. Audio-native evaluation catches issues that text analysis cannot.
Yes. Hamming tests both voice and chat agents with unified evaluation, metrics, and production monitoring. Whether your agent speaks or types, you get the same comprehensive QA platform—one set of test scenarios, one dashboard, one evaluation framework.
This multi-modal capability means teams building conversational AI don't need separate tools for voice and chat. Auto-generate scenarios, define guardrails, run regression tests, and monitor production—all in one platform regardless of modality.
Teams switching from developer-focused alternatives to Hamming cite faster time-to-value, less configuration overhead, and more consistent evaluation. While some platforms require weeks of configuration before running your first test, Hamming gets you testing in under 10 minutes.
The key difference is evaluation consistency: Hamming achieves 95-96% agreement with human evaluators by using higher-quality models and a two-step evaluation pipeline. Platforms that use cheaper LLM models often produce inconsistent pass/fail reasoning that engineers can't trust.
Developer-first doesn't mean developer-only. Hamming delivers engineering rigor (full REST API, CI/CD native, webhooks) with cross-functional accessibility (dashboard, reports, audio playback) so your whole team can collaborate on agent quality.
Yes. We offer startup and SMB-specific pricing designed to match your usage. Early-stage startups get pricing that scales with their team, while enterprise customers get custom plans with dedicated support and compliance features.
Talk to us to learn more about pricing options for your team.
Hamming serves startups and enterprises equally well. YC-backed startups run their first tests in under 10 minutes after a quick onboarding call. Enterprise teams get the same speed with additional compliance (SOC 2, HIPAA), dedicated support, and custom SLAs.
Unlike point solutions that force you to outgrow them, Hamming scales from day one. Start with 10 test cases, scale to 10,000. Add enterprise support when you need it. The platform grows with your team.
Many of our startup customers started testing the week they launched their voice agent and stayed with Hamming as they raised Series A, B, and beyond. No migration required.
