TLDR
- We built a new benchmark called "Bug In The Code Stack" (BICS) to test how well LLMs can find syntactic bugs in large Python codebases.
- GPT-3.5-Turbo showed lower accuracy on the BICS benchmark than the BABILONG benchmark at the same context length and target depth, indicating that LLMs struggle more on code-based tasks than text-based tasks at long context length.
- The hype is real. GPT-4o showed the best performance, closely followed by GPT-4-Turbo. The GPT-4-Series especially performed well at long context lengths compared to other models.
- Generally, longer context length resulted in lower accuracy. However, there were some exceptions to this.
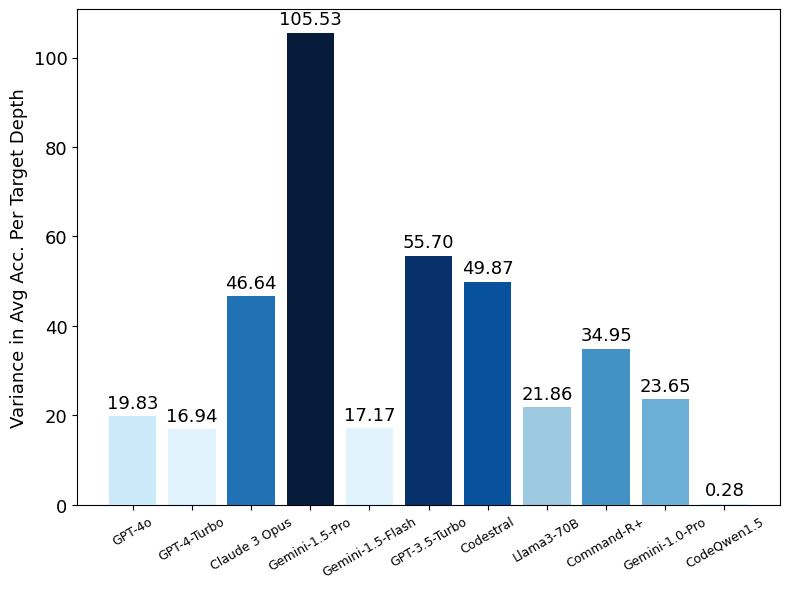
- Models react differently to the placement of the bug within the source code. GPT-3.5-Turbo and Claude 3 Opus were the most sensitive, and GPT-4-Series was the least sensitive. Generally, less sensitivity means a more robust model.
- Gemini 1.5-Pro is ~3x better than Gemini 1.0 Pro; as Google claimed, 1.5-Pro's performance stays constant across all context lengths and target depths.
- Codestral 22B performed on par with GPT-3.5-Turbo and Llama3-70B despite being a significantly smaller model.
Quick filter: If your model can’t reliably find a missing parenthesis in 25 pages of code, don’t trust it to review your core codebase unaided.
| Benchmark dimension | Values tested | Why it matters |
|---|---|---|
| Context length | 500 to 16K tokens | Measures long-context retrieval |
| Target depth | 0% to 100% | Tests bug placement sensitivity |
| Task type | Syntactic bug localization | Reflects real code analysis |
| Metric | Accuracy over 25 runs | Compares model robustness |
Motivation
As LLMs' context window sizes grow, their use as coding assistants for large codebases is increasing. It's crucial to understand how longer context lengths impact their performance.
The "needle in the haystack" analysis tests LLMs' ability to find specific information in long documents. Previous benchmarks like BABILONG focused on text tasks. Now, as LLMs are used more for coding, it's important to see how they perform on code tasks and if the task type affects their accuracy.
Experimental design
We developed a new benchmark called Bug In The Code Stack (BICS), which contains auto-assembled Python source code as the haystack and a syntactic bug placed within the source code as the needle. The LLM is tasked with finding the line number and the type of the bug.


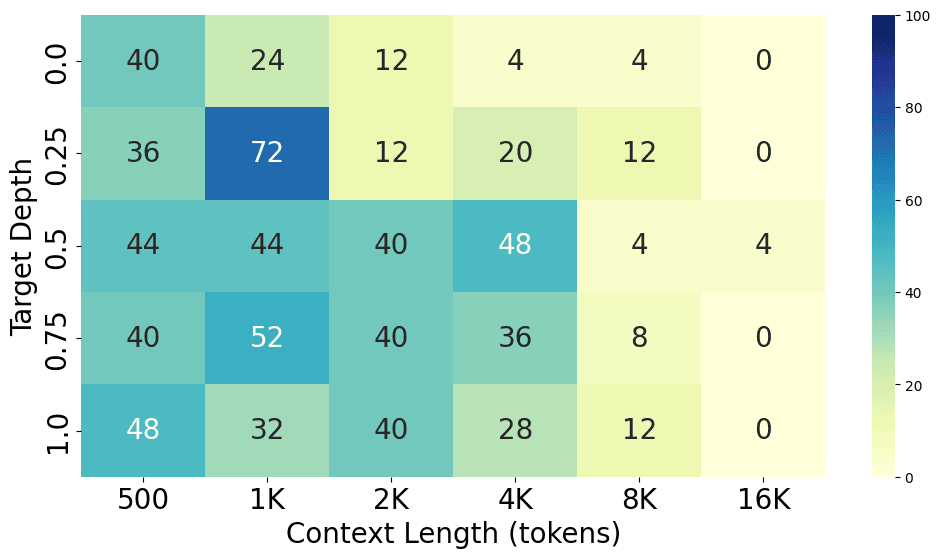
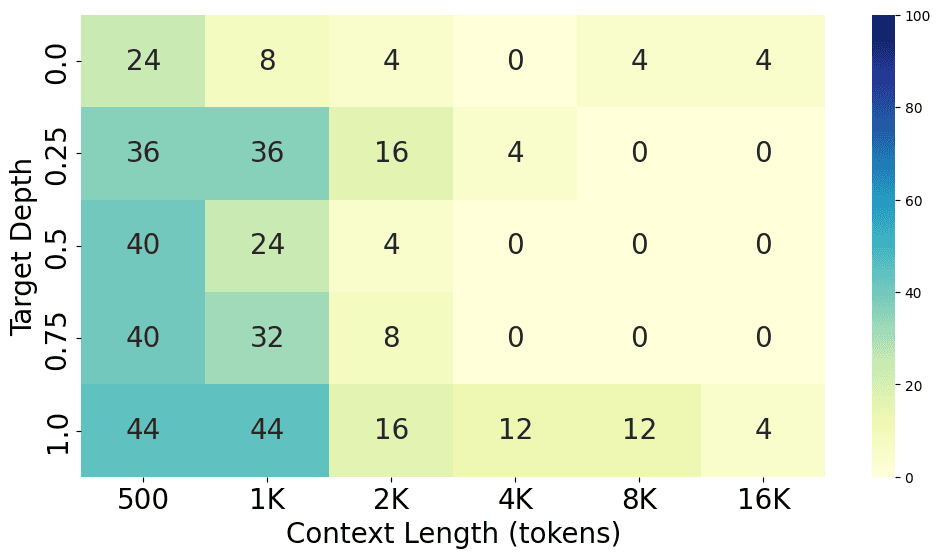
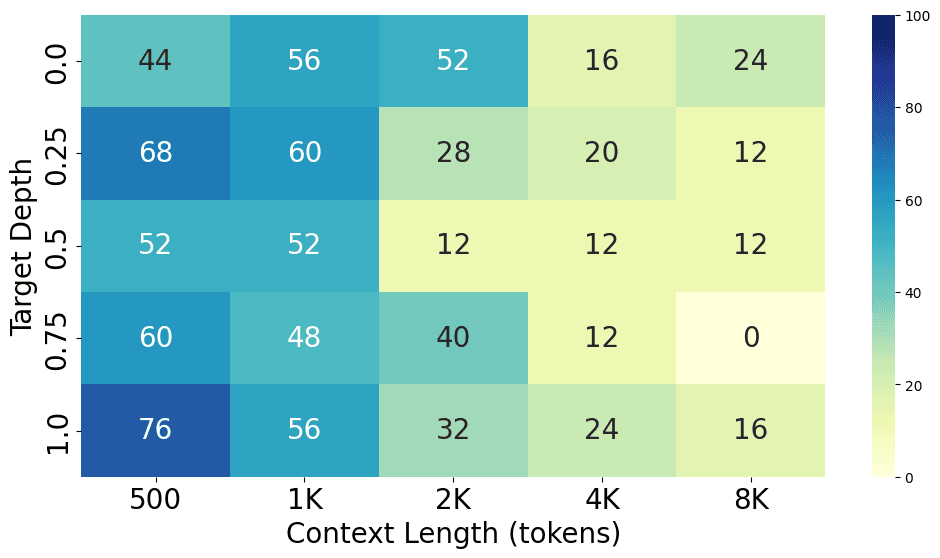
Each model was run on context lengths ranging from 500 tokens to 16K tokens and target depths ranging from 0% to 100%. We ran each experiment 25 times, and the average accuracy is shown in the following charts.
To give context, 16K tokens are around 25 pages long. The models are challenged to find a single syntactic bug, which could be as small as a missing parenthesis, within 25 pages of code! This benchmark poses quite a challenge to many of the models.
Comparing results on most popular models
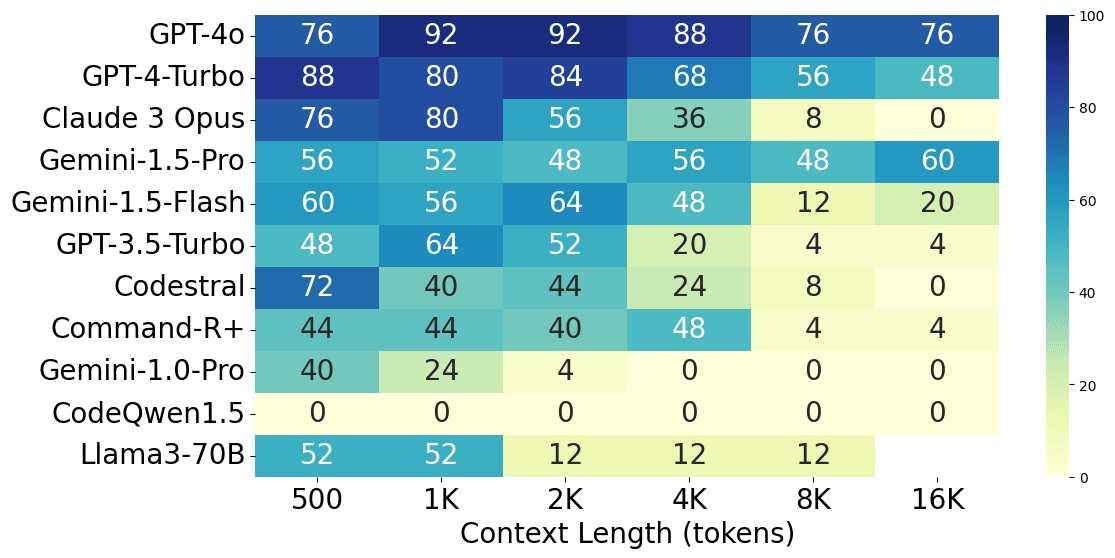
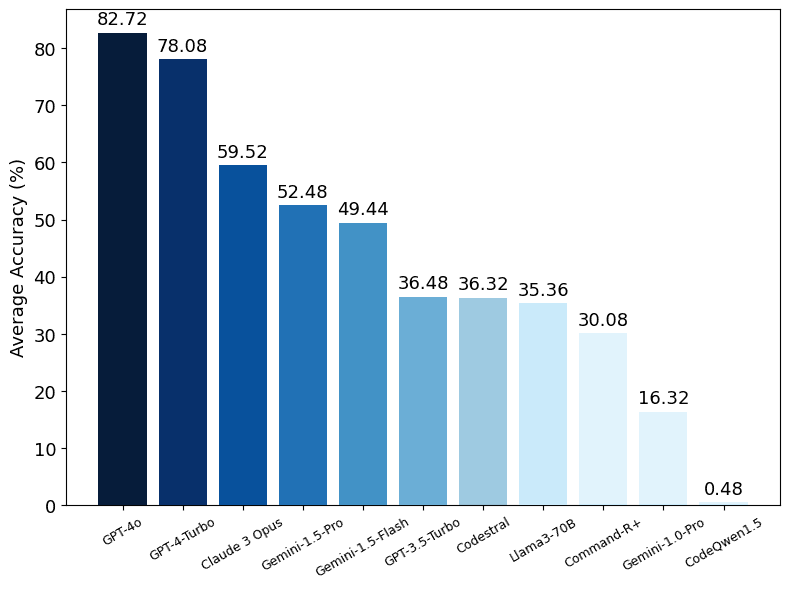
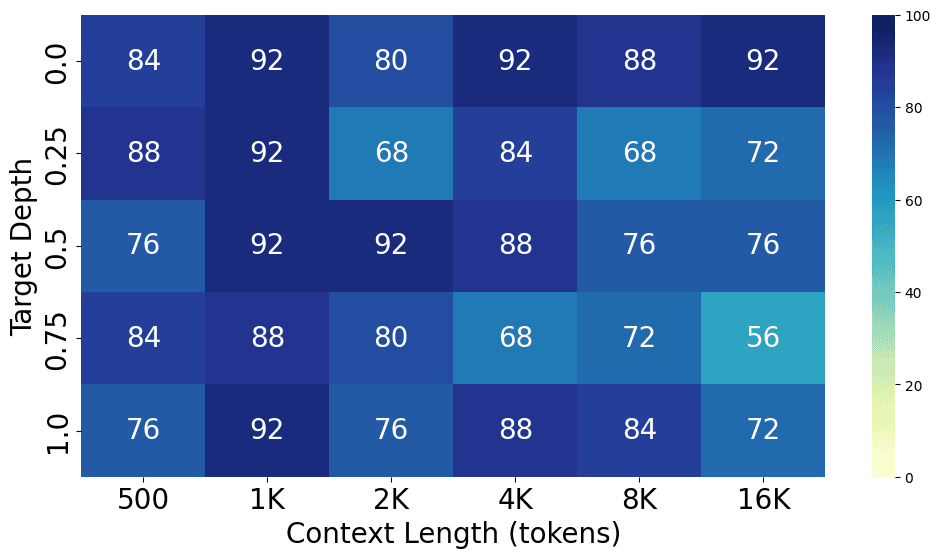
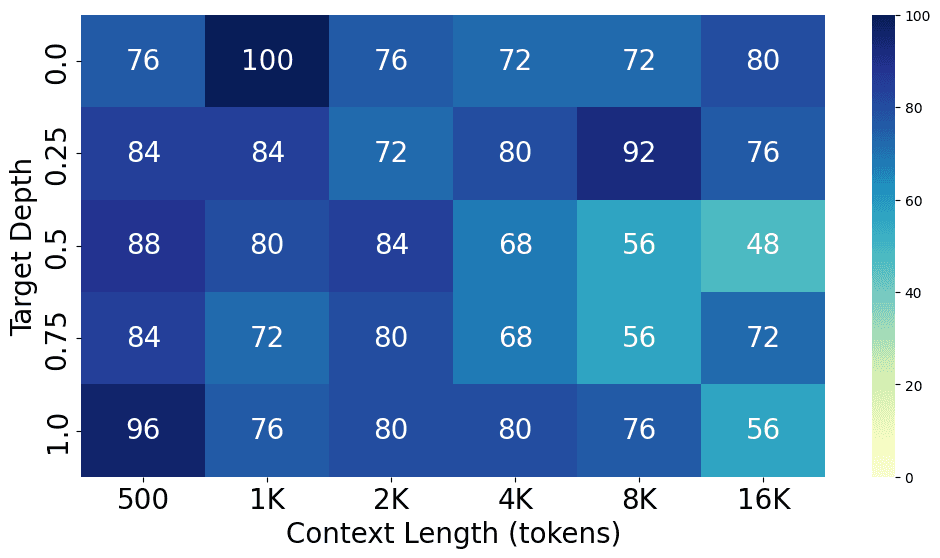
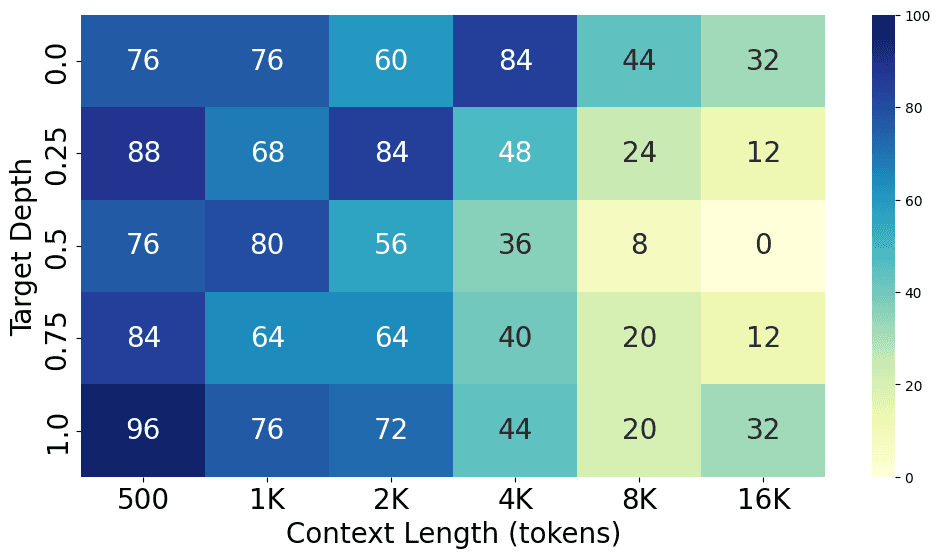
From the charts above, we can see the performance gap between different models, with GPT-4o performing the best at both short and long context lengths, closely followed by GPT-4-Turbo. Claude 3 Opus shows a similar level of performance at short context lengths but struggles at long context lengths. Additionally, GPT-3.5-Turbo, Codestral 22B, Llama3-70B, and Command-R+ all show similar performance levels.
Comparing BICS and BABILONG
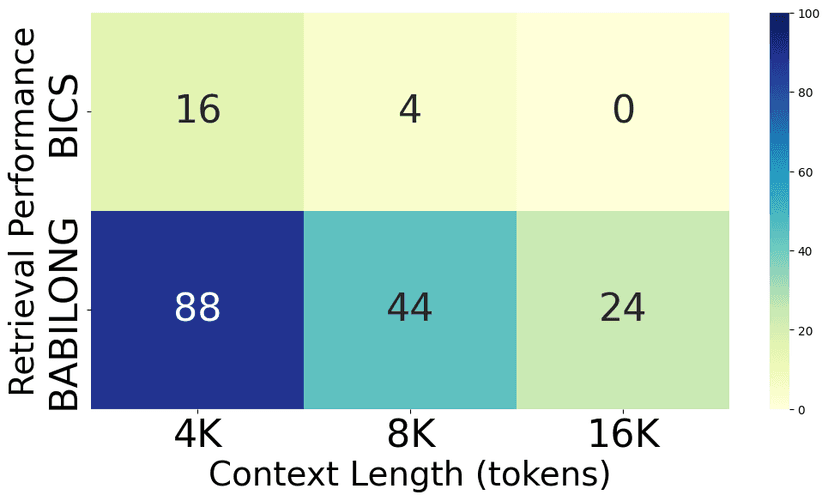
In addition, we see that LLMs display much lower accuracy on the BICS benchmark than the BABILONG benchmark. This indicates that LLMs struggle more at understanding long codebases than long text, hinting at a future improvement to the models for code comprehension capabilities.
Detailed results
Here are the detailed results for each model.
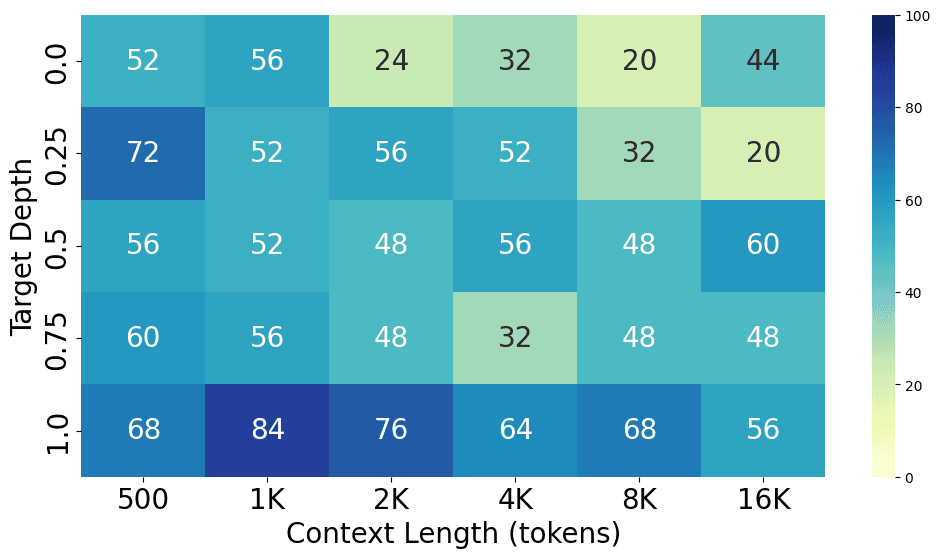
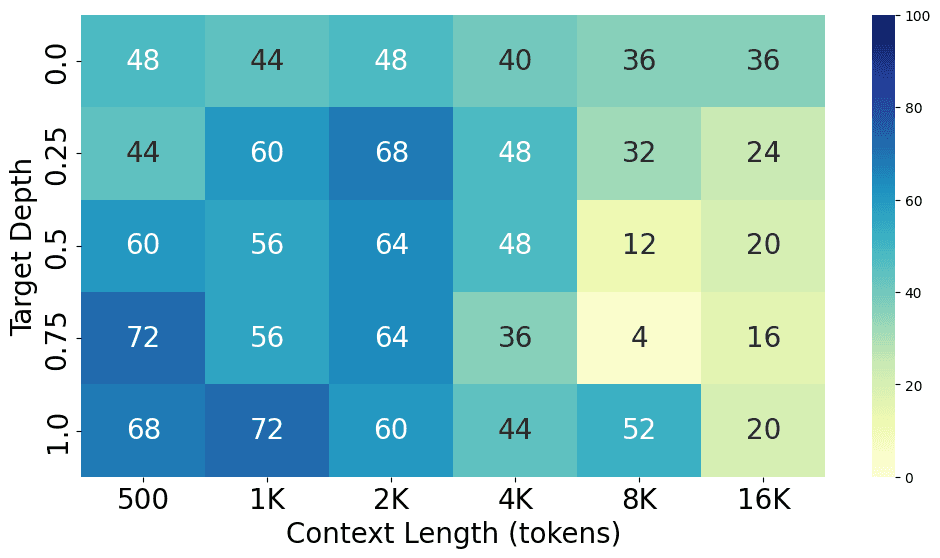
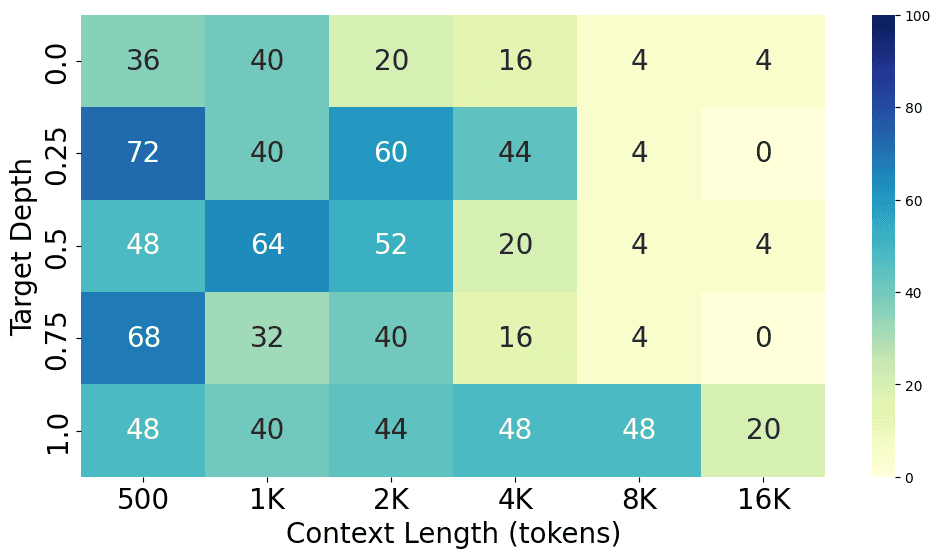
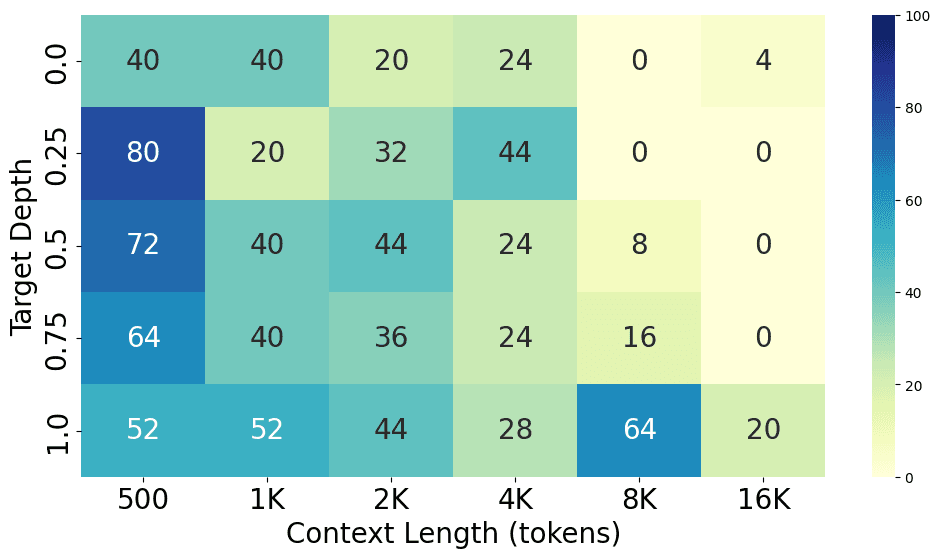
Future experiments
The "Bug In The Code Stack" benchmark presents a new challenge measuring LLMs' capability at long context lengths. In the future, we would also like to extend the benchmark by adding logical errors that cannot be detected using static code analyzers, which further helps evaluate the capabilities of the models. In addition, we can run experiments with different programming languages, such as Javascript or C++, and observe the performance difference.
Special thanks to Bingxu Hu and Sumanyu Sharma for helping structure the experiments and revising the article. We've open-sourced the benchmark Bug In The Code Stack. Any help to improve the benchmark or run it on additional models would be highly appreciated 🙂.