
👋 Sumanyu from @Hamming (S24)
TLDR: Are you struggling to make your RAG & AI agents reliable? We're launching our LLM Experimentation Platform to help eng teams speed up iteration velocity, root-cause bad LLM outputs, and prevent regressions.
Quick filter: If your iteration loop depends on “eyeballing a few examples,” you don’t have a reliable system yet.
🌟 Click here to try our LLM Experimentation Platform 🌟
Our thesis: Experimentation drives reliability
Previously, I ran growth focused eng and data teams at Tesla and Citizen. We learned that running experiments is the best way to move a metric. More experiments = more growth.
We believe the same is true for eng teams building AI products. More experiments = more reliability = more retention for your AI products.

Problem: Making RAG and AI agents reliable feels like whack-a-mole
Here's the workflow most teams follow:
- Tweak your RAG or AI agents by indexing new documents, adding new tools, changing the prompts, models or other business logic.
- Eyeball how well your changes improved a handful of examples you wanted to fix. Often ad-hoc and slow.
- Ship the changes if they worked.
- Detect regressions when users complain of things breaking in production.
- Repeat steps 1 to 4 until you get tired.
| Step | Manual pain point | How Hamming helps |
|---|---|---|
| Tweak | Unclear impact of changes | Structured evals on real traces |
| Eyeball | Slow, low-signal review | Automated scoring at scale |
| Ship | Risk of silent regressions | Gate changes with tests |
| Detect | Users complain first | Real-time production scoring |
Steps 2 and 4 are often the slowest & most painful parts of the feedback loop. This is what we tackle.
Our take: Use LLMs as judges to speed up iteration velocity
We use LLMs to score the outputs of other LLMs. This is the fastest way to speed up the feedback loop.
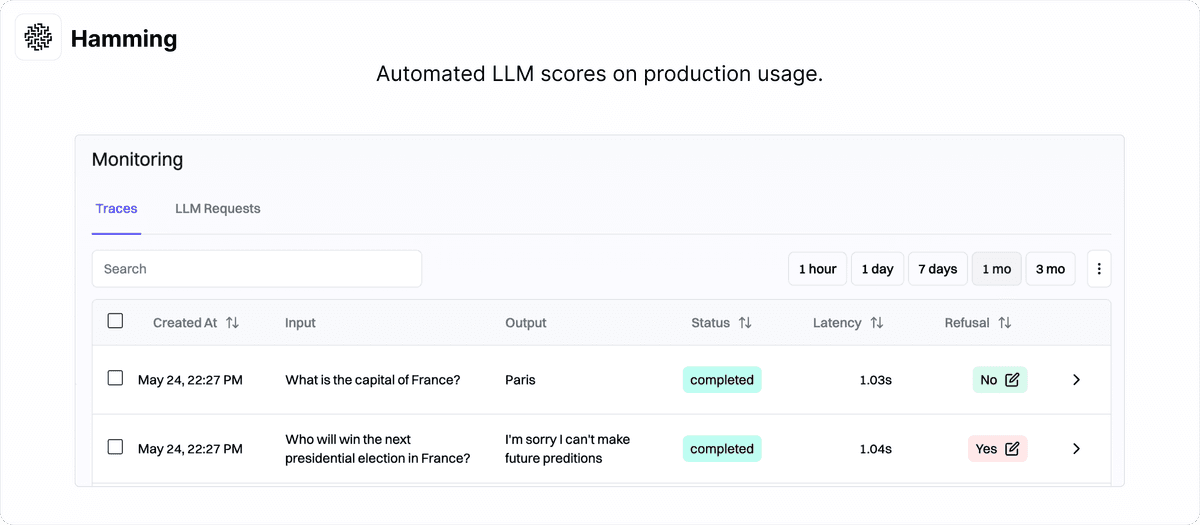
Prod: Flag errors in production, before customers notice
We go beyond passive LLM / trace-level monitoring. We actively score your production outputs in real-time and flag cases the team needs to double-click on. This helps eng teams quickly prioritize cases they need to fix.
Dev: Test new changes quickly and prevent regressions
We make offline evaluations easy, so you can make a change to your system and get feedback in minutes.
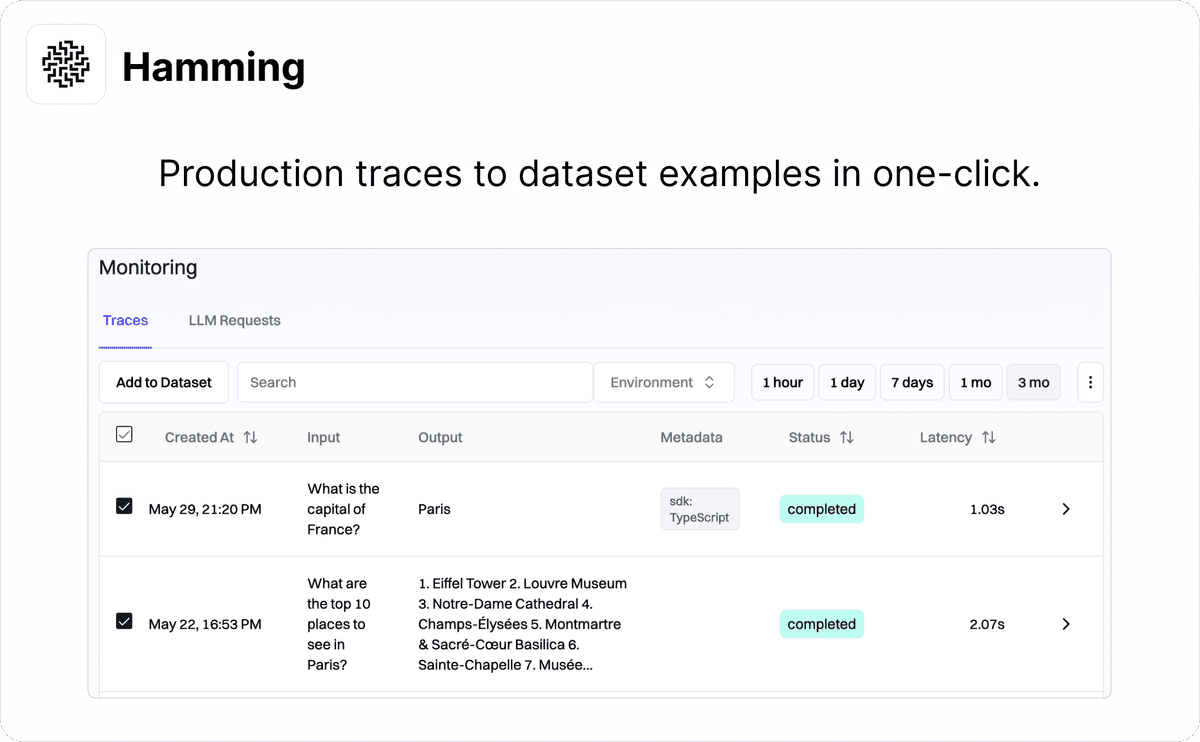
Easily create golden datasets
Offline evaluations are bottlenecked on a high-quality golden dataset of input/output pairs. We support converting production traces to dataset examples in one-click.
Diagnose between retrieval, reasoning or function-calling errors quickly
Differentiating between retrieval, reasoning and function-calling errors is time-consuming. We score each retrieved context on metrics like hallucination, recall and precision to help you prioritize your eng efforts where it matters.

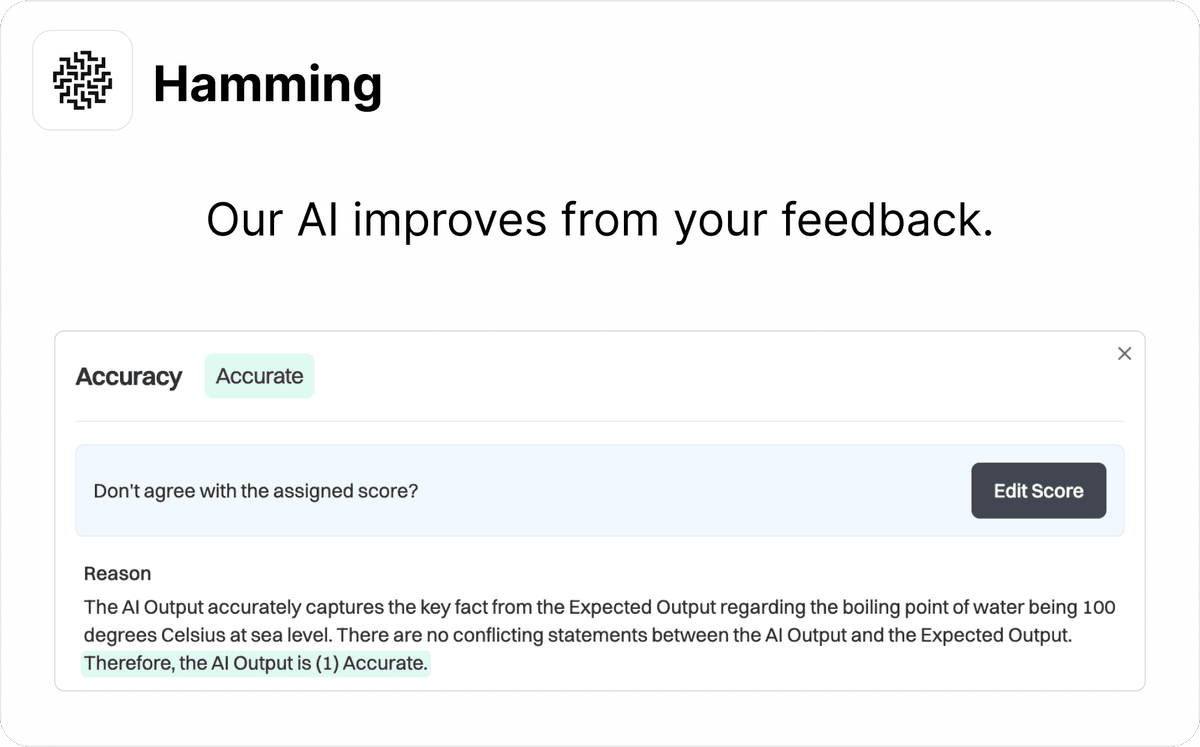
Override AI scores
Sometimes our AI scores disagree with your definition of "good". We make it easy to override our scores with your own preferences. Our AI scorer learns from your feedback.
Meet the team
Sumanyu previously helped Citizen (safety app; backed by Founders Fund, Sequoia, 8VC) grow its users by 4X and grew an AI-powered sales program to $100s of millions in revenue/year at Tesla.
Our ask
We previously launched Prompt Optimizer on BF that saved 80% of manual prompt engineering effort. In this launch, we showed how teams using Hamming to build reliable RAG and AI agents.
- YC Deal. 50% off our growth plan for next 12 months, 1:1 workshops, premium support, Patagonia Swag, more. ($10k+ worth of value) Link to our YC deal.
- Warm intros. We'd love intros to anyone you know who wants to make their RAG and AI agents more reliable. (including you!)
Email us here.
Book time on our calendly.
