
👋 Sumanyu from @Hamming; we're part of the upcoming S24 batch!
TLDR: Are you spending a lot of time hand-optimizing prompts? We're launching our Prompt Optimizer (new feature in beta) to automate prompt engineering. It's completely free for 7 days!
Quick filter: If you are spending more time tweaking prompts than shipping features, this is for you.
🌟 Click here to try our Prompt Optimizer 🌟
Convert your task into an optimized prompt in minutes
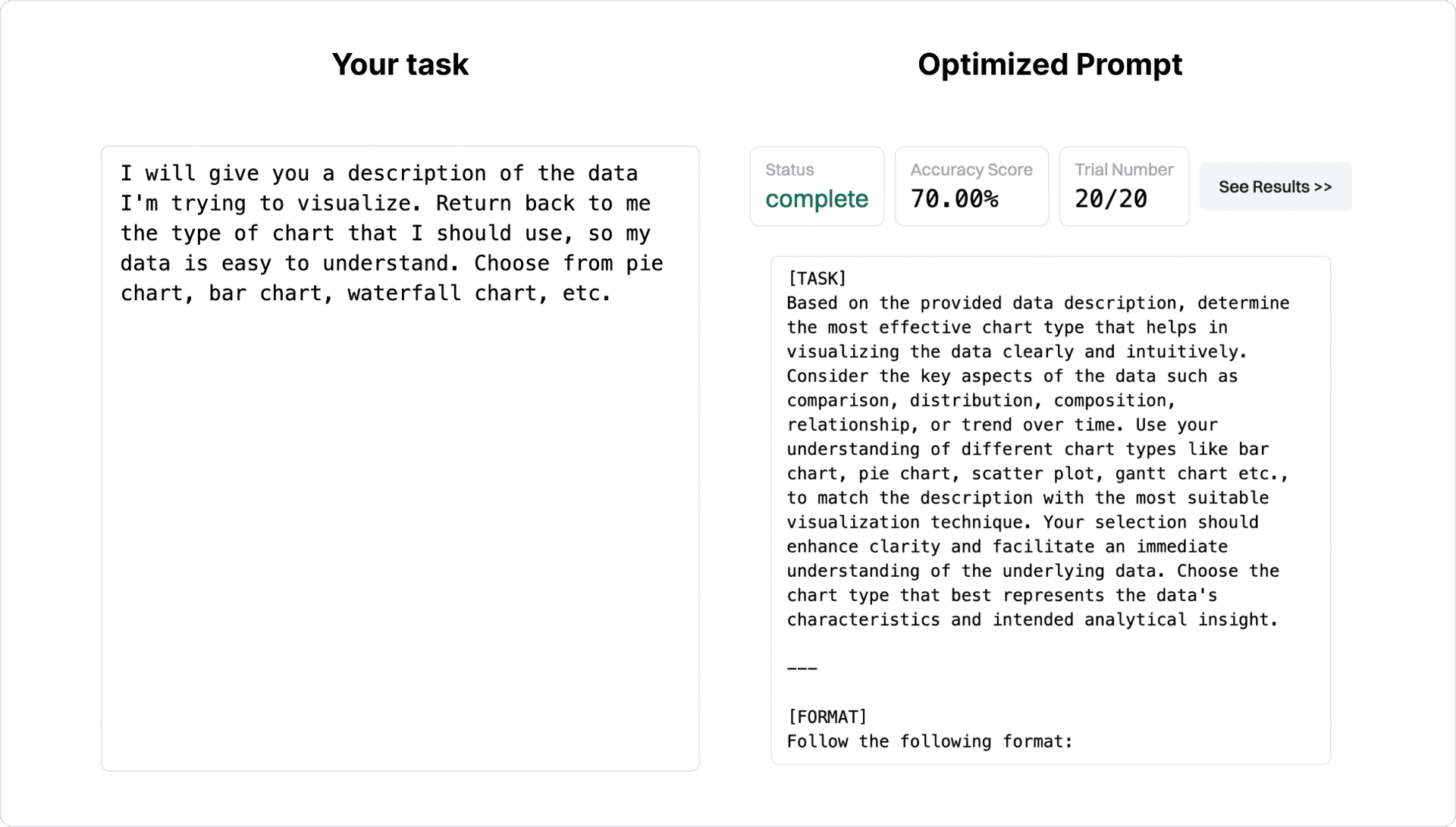
Thought experiment: What if we used LLMs to optimize prompts for other LLMs?

Problem: Writing prompts by hand is tedious
Writing high-quality and performant prompts by hand requires enormous trial and error. I’ve done this loop too many times. Here's the usual workflow:
- Write an initial prompt.
- Measure how well it performs on a few examples in a prompt playground. Bonus points if you use an evals platform like Hamming to automate this flow.
- Tweak the prompt by hand to handle cases where it's failing.
- Repeat steps 2 & 3 until you get tired of word-smithing.
| Manual step | What goes wrong | Optimizer benefit |
|---|---|---|
| Write | Prompt starts too generic | Generates stronger variants |
| Measure | Few examples, noisy feedback | Scores at scale with LLM judge |
| Tweak | Endless trial and error | Iterative improvement from outliers |
| Repeat | Slow cycles | Faster convergence on better prompts |
What's worse, new model versions often break previously working prompts. Or say you want to switch from OpenAI GPT3.5 Turbo to Llama 3. You need to re-optimize your prompts by hand. ❌
Our take: use LLMs to write optimized prompts
Describe your task, add some examples, and click run.
Behind the scenes, we use LLMs to generate different prompt variants. Our LLM judge measures how well a particular prompt solves the task. We capture outlier examples and use them to improve the few-shot examples in the prompt. We run several "trials" to refine the prompts iteratively.
Benefits:
- No more tedious word-smithing.
- No more scoring outputs manually by hand.
- No need remembering to tip your LLM or asking it to think carefully step-by-step. We all do it, but it shouldn't be required.
Meet the team
Sumanyu previously helped Citizen (safety app; backed by Founders Fund, Sequoia, 8VC) grow its users by 4X and grew an AI-powered sales program to $100s of millions in revenue/year at Tesla.
Our ask
In this launch, we showed how we help teams optimize each prompt. In our next launch, we'll walk through how teams use Hamming to optimize their entire AI app.
- YC Deal. Our optimizer is completely free for the next 7 days!
- Feedback. We want you to throw real world tasks at our optimizer and tell us what's working and where we can be better.
- Warm intros. We'd love intros to anyone you know who writes a lot of prompts by hand. (including you!)
If you have any questions or need help, please contact our support team.
Email us here.
Book time on our calendly.
