
The short version: There's no "best" stack - there's the stack that fits what you're actually trying to do. I've seen teams waste months building custom when they should've used Retell, and teams struggle on managed platforms when they clearly needed to own the infrastructure. This guide won't tell you what to pick. It'll give you the framework to figure it out yourself.
Quick filter: Need audit trails for compliance? Cascading architecture. Latency is the only thing that matters? Look at speech-to-speech. Not sure yet? Keep reading.
Related Guides:
- Build vs. Buy: Why 95% of Teams Buy Voice Agent Testing - Full cost analysis for testing infrastructure
- How to Evaluate Voice Agents: Complete Guide - 5-Dimension VOICE Framework
- How to Monitor Voice Agent Outages in Real-Time - 4-Layer Monitoring Framework
- ASR Accuracy Evaluation for Voice Agents - 5-Factor ASR Framework
- Multilingual Voice Agent Testing - Testing across languages
How to Choose the Best Voice Agent Stack
Here's the pattern I see over and over: team builds a voice agent, demo works great, they launch, and within a month something's broken that they can't explain. Latency spikes. Random hallucinations. Calls dropping. They assume it's the LLM and start prompt engineering. Sometimes that's right. Usually it's not.
We did an audit last month - company had spent $40K on prompt iterations. Forty thousand dollars. Want to know what the actual problem was? Their STT was clipping the first 200ms of every utterance. The transcripts were garbage before the LLM ever saw them. No amount of prompt work was going to fix that.
Look, the individual components are fine. Deepgram, ElevenLabs, GPT-4, whatever - they all work. The issue is almost never that you picked a "bad" component. It's that you assembled good components without thinking through how they'd interact at scale, or what happens when OpenAI has a rough day and your latency triples.
I'm going to walk through a framework for thinking about this. Fair warning: there are a lot of tables and benchmarks below. Use them as starting points. Your specific use case matters more than any benchmark I can show you.
Methodology Note: Component benchmarks and latency thresholds in this guide are based on Hamming's analysis of voice agent interactions across 10K+ voice agents (2025). Hamming's platform has 10M+ mins protected.Published provider specifications informed comparisons. Actual performance varies by implementation, traffic patterns, and configuration. Cost estimates reflect publicly available pricing as of December 2025.
What's Actually in a "Stack"?
When people say "voice agent stack" they're usually talking about the full pipeline: how calls come in (telephony), how audio becomes text (ASR/STT), how text becomes decisions (LLM + tools), how decisions become speech (TTS), and - the part everyone forgets - how you know any of it is actually working (monitoring/QA).
Most teams get the first four right and completely ignore the fifth. Don't do that.
The Selection Framework
I'm going to give you a scoring framework here. Honestly, I'm a little ambivalent about frameworks - they can make complex decisions feel falsely simple. But having some structure beats arguing in circles for weeks, which is what happens otherwise.
The Four Dimensions
| Dimension | Key Questions | Weight |
|---|---|---|
| Architecture | Cascading vs S2S? Hybrid needed? | 30% |
| Components | Which STT/LLM/TTS meet your requirements? | 25% |
| Platform | Build vs buy? Time-to-market constraints? | 25% |
| QA Layer | How will you test, monitor, and improve? | 20% |
Quick Decision Matrix
Use this matrix to quickly narrow your options:
| If you need... | Choose... | Why |
|---|---|---|
| Fastest time-to-production (<1 month) | Retell or Vapi | Pre-integrated components, visual builders |
| Lowest latency (<500ms) | Speech-to-speech + custom build | S2S models eliminate text layer overhead |
| Maximum control + auditability | Cascading + LiveKit/Pipecat | Full visibility at each layer |
| Compliance (HIPAA, SOC2) | Bland AI or custom build | Clear audit trails, data residency control |
| Cost efficiency at scale (>50K mins/month) | Custom build with LiveKit | Up to 80% savings vs managed platforms |
| Multilingual support (10+ languages) | Cascading with Deepgram + ElevenLabs | Best accuracy across languages |
These are starting points, not gospel. The "fastest time-to-production" platforms will get you live quickly, but roughly half the teams we talk to migrate off within 12 months once they hit scale or customization limits. Factor that into your decision.
Stack Scoring Rubric
Score each dimension from 1-5 to compare options:
| Criterion | 1 (Poor) | 3 (Adequate) | 5 (Excellent) |
|---|---|---|---|
| Latency | 3+s end-to-end | 1.5-3s | 1.5s |
| STT Accuracy | >12% WER | 8-12% WER | <8% WER |
| TTS Quality | Robotic, noticeable | Natural for most users | Indistinguishable from human |
| Time-to-Production | 3+ months | 1-3 months | 1 month |
| Cost at 10K mins | >$3,000/month | $1,000-3,000 | <$1,000 |
| Observability | Logs only | Basic metrics | Full tracing + audio replay |
| Customization | Locked configuration | API access | Full source control |
Scoring thresholds:
- 28-35: Production-ready stack
- 21-27: Viable with optimizations
- <21: Significant gaps - reconsider architecture
One thing these scores don't capture: how much your specific use case matters. A 3-second latency that's "poor" for a real-time assistant might be perfectly fine for a voicemail transcription bot. Score against your actual requirements, not industry averages.
Sources: Scoring thresholds based on Hamming's stack evaluation across 10K+ voice agents (2025). Latency targets aligned with conversational turn-taking research (Stivers et al., 2009). Cost benchmarks reflect publicly available pricing at time of publication.
The Big Architecture Decision
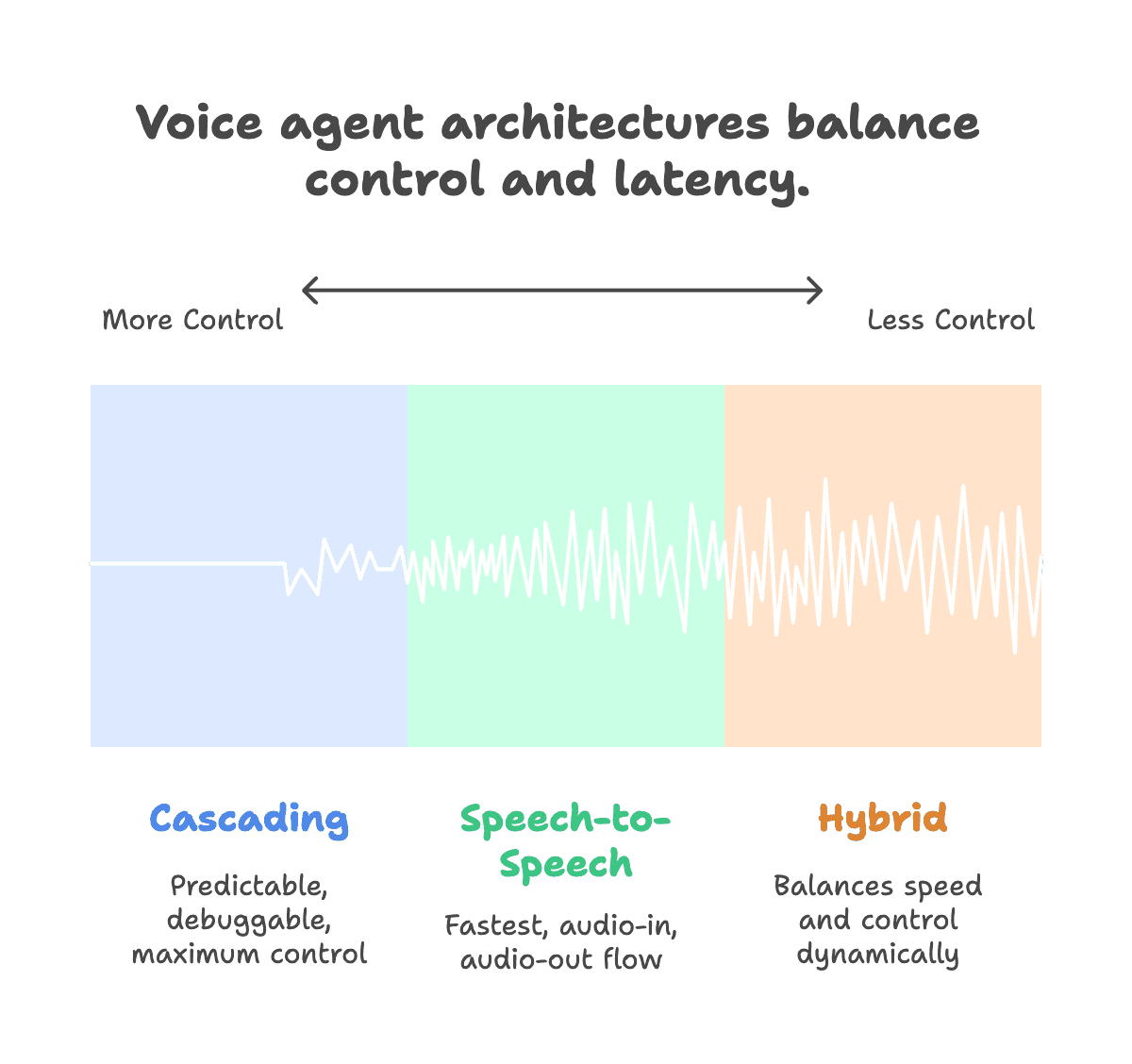
Before you even think about vendors, you have to decide: cascading or speech-to-speech? This is the choice that constrains everything else.
Here's the honest trade-off nobody wants to admit:
Cascading (STT → LLM → TTS) gives you visibility. When something breaks, you can actually see where. You get transcripts, you get LLM reasoning, you can debug. The downside? It's slow. You're looking at 2-4 seconds end-to-end in good conditions.
Speech-to-speech is fast - like, 500ms fast. Audio goes in, audio comes out. But good luck figuring out why the agent said something weird. There's no intermediate text to inspect. I've seen compliance teams kill S2S projects because they couldn't produce audit trails.
How Cascading Actually Works
Most production voice agents run cascading. Here's the flow:
- Audio → Text (100-300ms): Something like Deepgram turns speech into text. This is where accents and background noise bite you.
- Text → Decisions (300-900ms): GPT-4 or whatever LLM you're using figures out what to say. This is where prompt engineering actually matters.
- Decisions → Audio (300-1200ms): ElevenLabs or Cartesia generates the voice. This is where "sounding human" either works or doesn't.
Total latency: 2-4 seconds when everything's working. But "when everything's working" is doing a lot of heavy lifting there. I've seen this stretch to 6+ seconds when one provider has a bad day.
Speech-to-Speech: Fast but Opaque
S2S models like OpenAI's Realtime API are genuinely impressive. 500ms response times. The conversation feels natural. But here's what they don't mention in the marketing: when the agent says something wrong, you have almost no visibility into why.
I know of at least three companies who went all-in on S2S, got excited about the latency numbers, then had to rip it out because their compliance team asked "can you show me what the agent was thinking when it gave that wrong answer?" and the answer was no.
The Reality: Most Teams End Up Hybrid
Here's what I actually see working in practice: use S2S for the parts where speed matters and risk is low (greetings, simple acknowledgments), switch to cascading when you need auditability (transactions, compliance-sensitive stuff). LiveKit makes this mid-conversation switching possible. It's more work to set up but it's usually the right answer.
The Components (Where Things Actually Break)
Now let's get into the individual pieces. I'm going to give you comparison tables but please - please - don't just pick the one with the best numbers. Test with your actual use case.
STT: Where Most Failures Actually Start
I'd estimate 40% of the "agent problems" we see are actually STT problems. The transcript is wrong before the LLM even gets it. But teams blame the LLM because that's where the output comes from.
Test STT with your actual audio. Accents matter. Background noise matters. Domain vocabulary matters. A model that scores 93% on benchmarks might score 75% on your specific user base.
| Provider | Avg. Latency | Key Differentiator | Best For |
|---|---|---|---|
| Deepgram Nova-3 | Under 300ms | 94.74% accuracy for pre-recorded, 93.16% for real-time (6.84% WER). Industry-leading performance in noisy environments. | Multilingual real-time transcription, noisy environments, self-serve customization. |
| AssemblyAI Universal-1 | ~300ms (streaming) | 93.4% accuracy (6.6% WER) for English. Immutable streaming transcripts with reliable confidence scores. | Live captioning, real-time applications needing stable transcripts. |
| Whisper Large-v3 | ~300ms (streaming API) | 92% accuracy (8% WER) for English. Supports languages with <50% WER, strongest in ~10 major languages. | Multilingual applications, zero-shot transcription for diverse languages. |
Sources: Deepgram Nova-3 benchmarks from Deepgram Nova-3 announcement. AssemblyAI data from Universal-1 release. Whisper benchmarks from OpenAI Whisper paper (Radford et al., 2023). Latency figures from Hamming internal testing (2025).
Accuracy numbers change quarterly as providers push updates. We've seen 2-3% swings in WER after major model releases. The latency figures are more stable, but test with your actual audio - accents and background noise can swing accuracy by 10%+ from these benchmarks.
Engineering Insight: Fine-tuning STT for domain-specific vocabulary (medical terms, product names, internal jargon) is a common and necessary step for production-grade accuracy.
LLMs: Not Actually the Hard Part
Hot take: for most voice agents, the LLM is the least of your problems. GPT-4, Gemini, Claude - they all work fine for the kinds of conversations voice agents typically handle. The real issues are almost always upstream (bad transcripts) or downstream (weird TTS artifacts).
That said, time-to-first-token matters a lot for conversational feel, and tool-calling reliability matters if you're doing actual work in the conversation.
| Model | Time-to-First-Token | Key Differentiator | Best For |
|---|---|---|---|
| Gemini 2.5 Flash | 300ms TTFT, 252.9 tokens/sec | Strict instruction adherence and reliable tool use. | Workflows demanding predictable, structured outputs. |
| GPT-4.1 | 400-600ms TTFT | Strong tool calling and reasoning capabilities. | The default choice for complex, multi-turn conversations. |
Sources: Gemini 2.5 Flash benchmarks from Google AI Studio. GPT-4.1 data from OpenAI API documentation. TTFT measurements from Hamming voice agent testing across production workloads (2025).
Key Consideration: Most voice agent calls use less than 4K tokens. Don't pay for large context windows you won't use.
TTS: The Brand Problem Nobody Warned You About
TTS is weird because the "best" option isn't always the right option. The voice that sounds most natural to you might sound weird to your users. The voice that works for a consumer app might feel wrong for enterprise sales. This is surprisingly subjective and domain-dependent.
| Provider | Latency | Key Differentiator |
|---|---|---|
| ElevenLabs Flash v2.5 | ~75ms | Ultra-low latency with 32 language support. |
| ElevenLabs Turbo v2.5 | 250-300ms | Natural voice quality with balanced speed. |
| Cartesia Sonic | 90ms streaming (40ms model) | Very realistic voices at competitive pricing. |
| GPT-4o TTS | 220-320ms | Promptable emotional control and dynamic voice modulation. |
| Rime AI | Sub-200ms | Best price-to-performance ratio at scale ($40/million chars). |
Sources: ElevenLabs latency from ElevenLabs API documentation. Cartesia Sonic benchmarks from Cartesia product page. GPT-4o TTS from OpenAI TTS documentation. Rime AI pricing from official pricing page. Latency validated through Hamming internal testing (2025).
The voice quality numbers are subjective and domain-dependent. We had a healthcare client reject the "best" TTS option because it sounded too casual for appointment reminders. Budget $5-10K and two weeks for voice selection if brand consistency matters. It's not a decision you want to revisit after launch.
Key Consideration: Test TTS options with your target user demographic. What sounds natural to one group may feel robotic to another.
Orchestration: The Part That Will Ruin Your Month
This is where I see internal builds fail most often. People underestimate how hard it is to make conversations feel natural. When should the agent start talking? When should it stop? What if the user interrupts? What if there's background noise that sounds like speech?
LiveKit Agents handles most of this well enough that you can ship something quickly. Pipecat gives you more control but you'll spend a lot of time getting turn-taking right.
One thing nobody tells you: your users will complain about being "cut off" more than anything else. Track false-positive interruptions obsessively.
Platform Options: Build vs Buy
"Should we use Retell/Vapi or build custom on LiveKit?" - I get this question constantly. The honest answer is it depends on time, money, and how weird your requirements are.
| Platform | Time to First Call | Monthly Cost (10K mins) | Key Strength | Key Limitation |
|---|---|---|---|---|
| Retell | 3 hours | $500 - $3,100 | Visual workflow builder for non-technical teams. | Least flexible; adds 50-100ms of latency overhead. |
| Vapi | 2 hours | $500 - $1,300 | Strong developer experience and API design. | Can become costly at high scale ($0.05-0.13/min total). |
| Custom (LiveKit/Pipecat) | 2+ weeks | ~$800 + eng. time | Complete control, lowest latency, up to 80% cost savings at scale. | Large up-front investment (2+ engineers for 3+ months). |
Sources: Platform pricing from Retell, Vapi, and LiveKit official pricing pages. Time-to-first-call estimates based on Hamming customer onboarding data across 10K+ teams (2025). Custom build cost estimates assume senior engineer rates and typical infrastructure costs.
- Choose a Platform (Retell/Vapi) if: You're a SaaS company adding voice features, validating a voice UX, or need to build and iterate without deep engineering dependency.
- Choose a Custom Build (LiveKit) if: You have unique architectural requirements, expect high volume, and have a strong engineering team ready for a significant, long-term commitment.
What to Actually Monitor
I could give you a nice framework here but honestly? Most teams overthink monitoring and end up tracking things that don't matter while missing things that do. Here's what I'd actually focus on:
Layer 1: Infrastructure Health
- What to Test: Time-to-first-word (<500ms), audio quality scores (no artifacts in 99.9% of calls), and SIP trunk reliability (connection stability, packet loss).
Layer 2: Agent Execution Accuracy
- What to Test: Prompt compliance, entity extraction accuracy (names, dates, addresses), and context retention across multiple turns. Most agents score 95% on happy paths but drop to 60% with background noise or accents, which is why teams need our solution. As one customer described it, a "powerhouse regression" system.
Layer 3: User Satisfaction Signals
- What to Test: Frustration markers (tracking words like "What?" or "I already said..."), conversation efficiency (turns vs. optimal path), and emotional trajectory. Many technically "successful" calls contain user frustration.
Layer 4: Business Outcome Achievement
- What to Test: End-to-end validation (did the order get created, appointment scheduled, or patient record updated correctly?), business logic verification (was the right product offered?), and revenue impact.
Your 30-Day Implementation Plan
A four-week sprint from architectural decisions to validated stack.
Honest caveat: this 30-day timeline assumes you have dedicated engineering time and clear requirements. Most teams we work with take 6-8 weeks because requirements shift, stakeholders have opinions about voice selection, and integration testing always takes longer than planned. Build in buffer.
Week 1: Define Your Non-Negotiables
- Document Constraints: Budget (per-minute cost at scale), latency targets, and deal-breakers like HIPAA compliance.
- Map Critical User Journeys: List the top 5 conversation flows and define success/failure for each.
Week 2: Hands-On Platform Testing
- Build Your Core Flow: Implement the same primary user journey on Retell and Vapi to compare developer experience and flexibility. If considering a custom build, scope a LiveKit demo.
- Evaluate Platform Maturity (Red Flags):
- Lack of a Self-Serve Trial: Platforms should let their product speak for itself. Gated demos can hide limitations.
- Poor or Outdated Documentation: This indicates the quality of support and developer experience to expect.
- Inactive Developer Community: A vibrant community is a resource for troubleshooting and identifying common issues.
Week 3: Component Deep Dive
- STT Shootout: Use 50+ recorded utterances from real users (with accents, background noise, and domain terms) to test each provider's accuracy and latency under your specific conditions.
- LLM & TTS Gauntlet: Create 20 complex, multi-turn conversation scripts to test instruction following. Blind test TTS options with target users and ask which sounds more "trustworthy."
Week 4: Make Your Decision
- Architecture Choice:
- Need production in < 1 month? → Platform (Retell/Vapi).
- Processing < 10K minutes/month? → Platform.
- Unique requirements + engineering resources? → Custom.
- Compliance is critical? → A provider like Bland AI or a custom build with a clear audit trail.
- Final Validation: Build a proof-of-concept of your most complex use case with the chosen stack.
Wrapping Up
Look, I've given you a lot of information here. Probably too much. If you remember one thing: the stack you pick matters less than how well you understand its failure modes.
I've seen teams with "worse" stacks outperform teams with "better" stacks because they had better monitoring and responded to problems faster. The voice AI space is still immature enough that everything breaks sometimes. Your job is to know when it breaks and fix it before users notice.
The teams that succeed aren't the ones who picked the perfect architecture on day one. They're the ones who shipped something reasonable, watched it like hawks, and iterated when things went wrong. That's it. That's the whole secret.
If you're still reading and you're not sure where to start: pick a managed platform, get something in production, see what breaks, and make decisions from there. You'll learn more from two weeks of real traffic than from another month of architecture diagrams.
